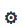Query by Video for Surgical Activities
Last updated: May 10, 2018
Summary
Feedback is a crucial component needed for one to improve. However, manually providing feedback on a procedure done by a surgeon is tedious, and requires the expertise of a colleague within the same field. Because of this, there has been a push to automate the process of generating feedback for a surgeon given information about the surgery itself. If the ability to find videos in a database that are similar in actions to the query works at a high resolution, it could be possible to construct novel feedback from any existing commentary of the database videos for the query. Similarly, the skill of surgery video clip can be inferred as well. Such information would decrease the manpower necessary to train a novice surgeon, as well as advance the ability for surgeons to quickly find areas to improve. This project is part of a larger overarching project studying clips of Cataract Surgery.
Students: Felix Yu and Gianluca Silva Croso
Mentor(s): Tae Soo Kim, Dr. Swaroop Vedula, Dr. Gregory Hager, Dr. Haider Ali


Background, Specific Aims, and Significance
Deliverables
Expected: (May 5 - done)
Validate our model by analyzing similarity scores activity clips in our dataset with target accuracy 30% on single-frame extractor, 60% after including temporal features
Submit a paper-style report documenting our findings
Maximum: (May 10 - done)
Use tool tip annotations (simulated if real are not available) to improve classification accuracy
Technical Approach
The figure above describes the current proposed structure of how we will query by video. As can be seen, the three most prominent components of the diagram are the following:
The frame-by-frame feature extractor. This initial neural network will take in a video clip of an arbitrary duration and for each frame of the clip, turn the 2-D image into a single vector that encodes the image. This will produce a 2-D matrix, where one dimension contains the time-series, and the other dimension contains the features.
The video descriptor extractor. This is also a neural network, taking in the output matrix of the previous network and condensing the features down to one dimension. The architecture of this network will be designed to capture any motion that can be found through the time-series. The output is a 1-D video descriptor.
The similarity metric. Since each video is now associated with a 1-D descriptor, a proper similarity metric will be able to take in two descriptors and output a value that assigns an interpretable value of how alike the two videos are.
This splits our project into the following steps.
Design and train a frame-by-frame extractor network architecture that will try to predict the activity (phase of the surgery) based on very brief segments alone. Using PyTorch, an open-source Python library, we plan implementing a convolutional 3-D network [6]. Afterwards, we will train this network using triplet loss [5]. Currently, this is producing poor results, but preliminary testing of an alternative, the SqueezeNet architecture trained using cross entropy shows promising results.
Design a network architecture that will take in the previous network’s output and again predict the activity of the clip, but now taking into account the temporal component. Again, we can do this using PyTorch, and use a temporal convolutional network [4] to capture motion related information in the input. We will still define our error metric with the triplet loss function, and again train to predict the activity class of the video. Furthermore, we plan on looking into how Recurrent Neural Networks using LSTM nodes can perform the same task.
Create a proper similarity metric. In this case, two clips that are of the same activity should be predicted to be very similar, while two clips of different activities will not. One method of designing the similarity metric is to incorporate this metric as a layer within the neural network, and allow the network to learn a proper metric calculation method. However, other simple metrics such as Euclidean distance will be considered as well.
In order to improve classification accuracy, we will use tool presence annotations for each frame and fuse that information with the spacial features to train the temporal feature extractor. Such annotations can be obtained either through other trained machine learning pipelines such as those presented in the cataract grand challenge, or manually by specialists or through crowdsourcing. For this project, it will not be possible to obtain such annotations in a timely manner, and therefore we will simulate this data based on information provided by our mentors about which tools should appear in each class, with which probability and for what length of time.
Dependencies
| Dependency | Planned Solution | Solved by | Contingency plan |
| GPU processing | Obtain access to MARCC cluster under Dr. Hager’s group for both team members | 2/28 (SOLVED) | At least one team member already has access, so if necessary GPU jobs can be submitted on his account exclusively. |
| Machine Learning, statistics and linear algebra packages | There is plenty of open source packages available in Python. We are using PyTorch and Numpy, both available on the MARCC cluster. | 2/10 (SOLVED) | N/A |
| Annotated Training dataset | Dr. Vedula has provided over 60 videos of entire cataract surgeries, as well as annotations for which frames correspond to which activities, as well as skill levels of the surgery. | 2/21 (SOLVED) | Although we hope to obtain more data, this amount should be adequate for our needs. |
| Gianluca’s inclusion to iRB | Dr. Vedula listed required online courses as well as link for inclusion request | 2/15 (SOLVED) | N/A |
Milestones and Status
Milestone name: Set up
Description: Set up all parts of the project, including gaining access to the MARCC cluster and install all necessary Python packages for development.
Planned Date: February 26
Expected Date: February 28
Status: Done
Milestone name: Technology and libraries familiarity
Description: Gain necessary knowledge in PyTorch and LMDB to handle data processing and neural network modeling.
Planned Date: February 29
Expected Date: February 29
Status: Done
Milestone name: Data pre-processing
Milestone name: Frame-by-frame feature extractor
Description: Implement the 3-D convolutional network with triplet loss, along with any necessary helper functions. Train the model to predict activity. If accuracy is under 30% classification rate, discuss and make revisions to improve the model.
Planned Date: March 21
Expected Date: April 1
Status: Done
Milestone name: Frame-by-frame feature extractor revision
Milestone name: Video descriptor extractor
Milestone name: Similarity metric
Milestone name: Tool annotations
Milestone name: Paper-style report
Milestone name: Fine-tuning to novice skill (Removed from plan)
Milestone name: Skill level prediction (Removed from plan)
Milestone name: Skill ranking (Removed from plan)
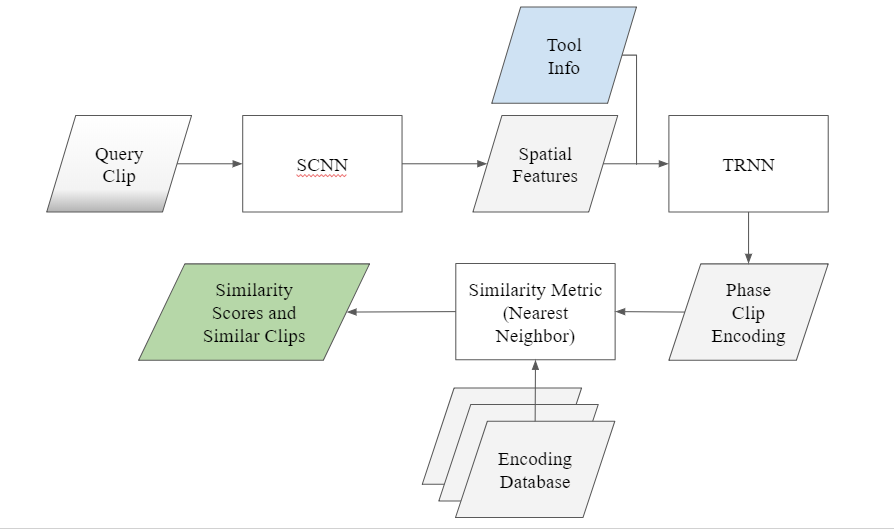
Original Timeline
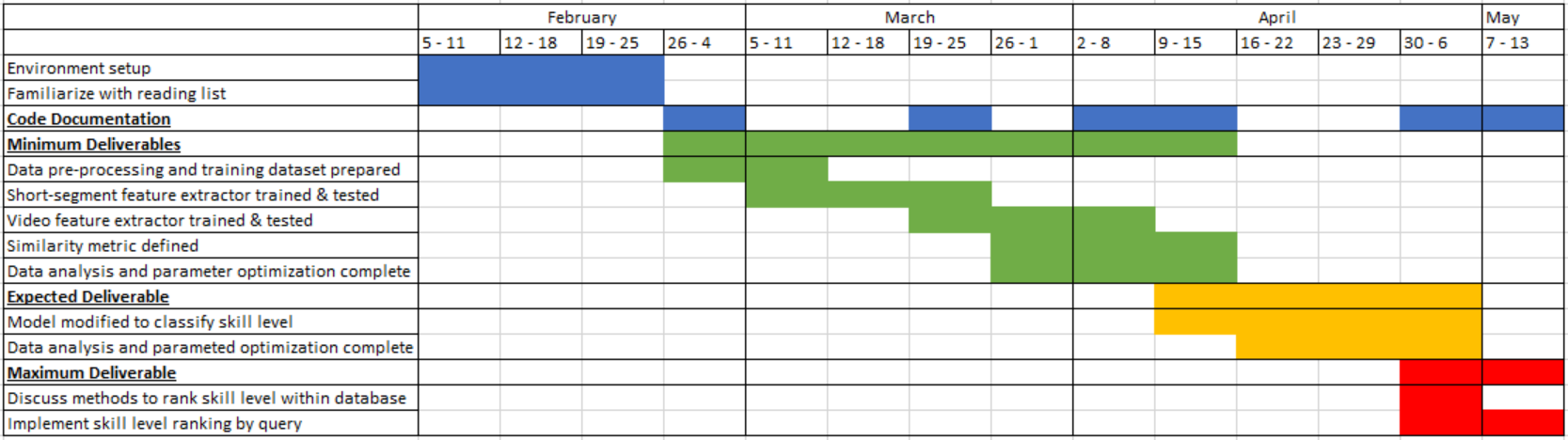
Updated Timeline
Reports and presentations
Project Plan
Project Background Reading
Project Checkpoint
Paper Seminar Presentations
Project Final Presentation
Project Final Report
Project code & documentation
Project Bibliography
Chopra, S., R. Hadsell, and Y. Lecun. “Learning a Similarity Metric Discriminatively, with Application to Face Verification.” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR05), 2005. doi:10.1109/cvpr.2005.202.
Gao, Yixin, S. Swaroop Vedula, Gyusung I. Lee, Mija R. Lee, Sanjeev Khudanpur, and Gregory D. Hager. “Query-by-example surgical activity detection.” International Journal of Computer Assisted Radiology and Surgery 11, no. 6 (April 12, 2016): 987-96. doi:10.1007/s11548-016-1386-3.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. doi:10.1109/cvpr.2016.90
Lea, Colin, Michael D. Flynn, Rene Vidal, Austin Reiter, and Gregory D. Hager. “Temporal Convolutional Networks for Action Segmentation and Detection.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. doi:10.1109/cvpr.2017.113.
Schroff, Florian, Dmitry Kalenichenko, and James Philbin. “FaceNet: A unified embedding for face recognition and clustering.” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. doi:10.1109/cvpr.2015.7298682.
Tran, Du, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. “Learning Spatiotemporal Features with 3D Convolutional Networks.” 2015 IEEE International Conference on Computer Vision (ICCV), 2015. doi:10.1109/iccv.2015.510.
F. Iandola, S. Song, M. Moskewicz, K. Ashraf, W. Dally J., K. Keutzer, SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size, ICLR Conference, 2017.
S. Hochreiter, J. Schmidhuber, Long Short-term Memory, Neural Computation 9(8):1735-1780, 1997
Zhao, R., Ali, H. and van der Smargt, P. (2017). Two-Stream RNN/CNN for Action Recognition in 3D Videos.
Lea, C., et. al. “Surgical Phase Recognition: from Instrumented ORs to Hospitals Around the World.” Paper presented at M2CAI workshop, (2016).
Other Resources and Project Files
Here give list of other project files (e.g., source code) associated with the project. If these are online give a link to an appropriate external repository or to uploaded media files under this name space.2018-02